4.4 Host I/O
Summary
- Several different testbed investigations demonstrated the feasibility of direct cell-based ATM host connections for workstation-class computers; this work established the basis for subsequent development of high speed ATM host interface chipsets by industry and provided an understanding of changes required to workstation I/O architectures for gigabit networking
- Variable-length PTM host interfacing was investigated for several different types of computers, including workstations and supercomputers; in addition to vendor-developed HIPPI interfaces, specially developed HIPPI and general PTM interfaces were used to explore the distribution of high speed functionality between internal host architectures and I/O interface devices
- TCP/IP investigations concluded that hardware checksumming and data-copying minimization were required by most testbed host architectures to realize transport rates of a few hundred Mbps or higher; full outboard protocol processing was explored for specialized host hardware architectures or as a workaround for existing software bottlenecks
- A 500 Mbps TCP/IP rate was achieved over a 1000-mile HIPPI/SONET link using Cray supercomputers, and a 516 Mbps rate measured for UDP/IP workstation-based transport over ATM/SONET; based on other workstation measurements it was concluded that, with a 4x processing power increase relative to the circa 1993 DEC Alpha processor used, a 622 Mbps TCP/IP rate could be achieved using internal host protocol processing and a hardware checksum while leaving 75% of the host processor available for application processing
- Measurements comparing the XTP transport protocol with TCP/IP were made using optimized software implementations on a vector Cray computer; the results showed TCP/IP provided greater throughput when no errors were present, but that XTP performed better at high error rates due to its use of a selective acknowledgment mechanism
- Presentation layer data conversions required by applications distributed over different supercomputers were found to be a major processing bottleneck; by exploiting vector processing capabilities, revisions to existing floating point conversion software resulted in a fifty-fold increase in peak transfer rates
- Experiments with commercial large-scale parallel processing architectures showed processor interconnection performance to be a major impediment to gigabit I/O at the application level; an investigation of optimal data distribution strategies led to a selection of application control for data distribution within the processor array in conjunction with use of a reshuffling algorithm to remap the distribution for efficient I/O
- Work on distributed shared memory (DSM) for wide area gigabit networks resulted in several latency-hiding strategies for dealing with large propagation delays, with relaxed cache synchronization resulting in significant performance improvements
Host I/O was one of the most challenging areas of the testbed effort. In general, it proved to be the Achilles' heel of gigabit networking -- whereas LAN and wide area networking technologies could be and were operated in the gigabit regime, many obstacles impeded achieving gigabit flows into and out of the host computers used in the testbeds.
A wide range of computers were used, ranging from vector and massively parallel supercomputers to single-processor workstations. Moreover, some testbeds experienced a dramatic change in the characteristics of the computers which were available for experiments. At the beginning of the project in 1990, state-of-the-art supercomputing was represented by Cray Research supercomputers with a peak performance of approximately 2 gigaflops. By 1994 supercomputer performance had increased by an order of magnitude or more, with the Cray vector architecture augmented by highly parallel machines such as the Paragon and CM-5.
While applications work in the testbeds emphasized the use of supercomputers, workstation-class computers also played an important role. Both Digital Equipment and IBM workstations were used as platforms for extensive high speed I/O hardware and software exploration. In the workstation case, advances in processor technology also allowed replacements with higher performance machines. However, project schedules precluded the redesign of I/O boards which were specially developed for the original workstation bus architectures, and so later bus technologies were for the most part not incorporated into this area of testbed work.
Against this backdrop, researchers in all of the testbeds investigated various aspects of the host I/O problem, which for this section we take to be the movement of data between an application running on a host and an external network, exclusive of the application software itself. This work spanned a large number of individual efforts and specific topics, with the latter including:
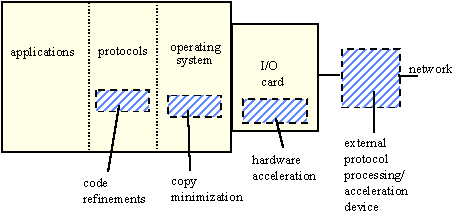
Figure 4-10 illustrates the focal points of this work within a generic host I/O architecture, with each effort typically including only a subset of the shaded components.
Figure 4-10. Generic Host I/O Architecture