 |
|
CNRI is conducting research, that is funded by DARPA, in the areas of Digital Libraries, Rights Management, and Classification of Digital Objects.
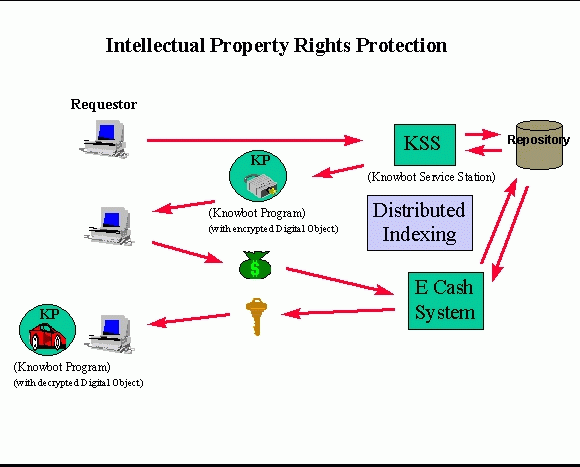 |
The design of an initial KSS with emphasis on the Knowbot Operating System (KOS), is now complete. A prototype has been fully implemented in the Python language running on a Unix platform. This prototype is operational and has been demonstrated. In addition, a small set of tools for submitting KPs and for tracking their status has been implemented and a GUI controlling station was written for tracking and launching KPs. This prototype KOS does not implement full code (i.e. Python stack) mobility, however an intermediate stage, of code mobility, was employed whereby the KP is restarted from the top of a well known entry point, having had only it's variable space restored. The KOS is described in greater detail in a paper titled Knowbot Programming: System support for mobile agents.
ILU (Inter-Language Unification, a CORBA compliant orb by Xerox PARC with intrinsic support for Python; see ftp://ftp.parc.xerox.com/pub/ilu/ilu.html) is used as the interface and transport mechanism between components and as the communication medium between different KOSs. MIME (Multipurpose Internet Mail Extensions, an IETF draft standard) is used for transferring Knowbot Programs between Knowbot Service Stations. Initially, only Knowbot Programs written in Python are being accepted. Each Knowbot Program will be executed as a separate Unix process, sharing the address space with a "supervisor" module. A separate "kernel" module keeps track of the whereabouts of all Knowbot Program processes and receives newly submitted Knowbot Programs. A Knowbot Program is run in Python's "restricted execution mode", which prevents it from doing damage to its environment -- all its interaction with the Knowbot Service Station's resources is through its supervisor.
In addition to what has been implemented in the prototype, the design of a number of additional features are nearing completion:
 |
Grail is an Internet browser written in Python, a free object-oriented, interpreted programming language. Grail versions 0.1 and 0.2 have already been released. Grail 0.3 is scheduled to be released in July 1996.
New features in Grail 0.3 include: user preference panels; a proper, disk-based cache; much improved handling of proper SGML lexical analysis; much better printing of HTML; implementation of many more HTML features, such as tables, frame sets, and more flexible list rendering; file uploading; client-side image maps; support for more image file formats including printing of same; improved performance; improved bookmarks; better use of the history stack for remembering the contents of forms and current page scroll position; improved proxy support; better security measures for applets, including the possibility to have a separate restricted execution environment for applets loaded from different servers. Much of the HTML 3.0 draft specification has now been implemented in Grail. Also many bugs have been fixed which were reported in previous versions of Grail.
The Grail disk cache is a fairly standard feature for a Web browser; the Grail cache, however, is more cautious about choosing pages to cache and is careful about checking that cached copies are not stale (subject to certain user controls). When the cache becomes full, some pages must be evicted from the cache to make room for new ones; unfortunately it is not clear that cached Web pages have the same working set behavior that makes LRU replacement strategies successful for most caches. The collection of data to analyze the behavior of Web caches over a long period of usage has been initiated.
Grail is a candidate delivery mechanism for the Knowbot Operating System (KOS). A Grail applet has been written which can submit a Knowbot Program to a Knowbot Service Station and monitor its status.
Automatic indexing, classification, and thesaurus-generating techniques can be applied to this personal information to develop more structured models of a user's view of his or her information space. Such techniques could include, for example, identifying the keywords that describe a particular mail folder or statistically describing the differences between two sub-folders included within that folder.
One of the primary difficulties is the relative inefficiency of traditional term weighting strategies in a distributed environment. In traditional information retrieval, term weights for a document are assigned using a collection-wide statistics -- a weight based on term frequency and inverse document frequency is typical. Applying traditional term weight strategies in a distributed system is harder. Distributed information retrieval is often based on a model where many independent servers index local document collections and a directory server (or a hierarchy of servers) guides users towards the independent indexes that will best satisfy their information needs. This model assumes that the documents stored at a particular server define a collection.
One of the key challenges, then, is to define an architecture that allows for the construction of collections that are independent of the location(s) of the documents in the collections. For example, the ACM Classification Scheme has a cleared mapped out hierarchy and has already been applied to many documents (in the ACM Computing Reviews magazine); using this base of already-classified documents, one can perform operations similar to document clustering to identifying and categorize other computer science documents.
An enabling technology for flexible distributing indexing is an indexing service station, which would be coupled with one or more repositories. The indexing service station would receive indexing agents (programs) from search services and execute them, allowing the search services to index information appropriate for their service while minimizing the inefficiency of moving the data to be indexed across the network to the search service.
Further information is available in a paper on Creating Collections with a Distributed Indexing Infrastructure.
Funding for this work is provided by the Defense Advanced Research Projects Agency (DARPA) under grant MDA972-95-1-0003.

tstrollo
7/3/96