

Wide area Packet Transfer Mode, or variable-length packet switching, was explored in both the Aurora and Casa testbeds. In addition, while not strictly a packet-switched technology, HIPPI was the basis for local area networking in four of the testbeds.
A major part of IBM's research in the Aurora testbed was focused on their Planet and Orbit gigabit PTM technology (originally named Paris and Metaring respectively) which had been under development prior to the start of the project. Their architectural premise was that, because of the small transmission times involved with networking at gigabit rates, reasonably large variable length packets could be handled along with short packets while still providing real-time quality of service to the portion of traffic requiring it.
The Planet switch was intended for wide area switching, working in conjunction with 1 Gbps Orbit local area buffered rings at each site. The switch is based on a modular architecture in which link adapter cards communicate through a 6 Gbps backplane. Individual packet processing is done in hardware, with routing updates and other control functions handled in software by an RS/6000 workstation attached to the switch via an Orbit ring. In addition to Orbit rings, link adapter cards can be connected to wide area links through use of a SONET and other types of non-Orbit adapters. Also, while originally intended as a non-ATM switch, IBM added a capability to deal with fixed-size ATM cells as a special case of the switch's more general PTM capability.
Planet switch prototypes were deployed at IBM and Upenn for use in Aurora experiments. Through the use of real application traffic supplemented by artificial traffic generators, significant new insights were obtained by IBM researchers concerning traffic management under heavy switch loading, synchronization requirements, and other aspects of switch-related network performance.
Network Systems Corporation (NSC) developed a commercial HIPPI switch product early in the testbed project, and these switches were used for local switching in the four testbeds which used HIPPI for local interconnection. As switches from other companies became available later in the project they were also used by some testbeds. These switches were based on non-buffered crossbar architectures and followed the ANSI standard for HIPPI switch control, typically providing either 8 or 16 ports operating at 800 Mbps.
Because the HIPPI protocol requires that a physical circuit be established prior to data transmission at each end of a HIPPI link, cascading two or more HIPPI switches in general introduces a significant potential for blocking relative to packet-switched operation. A method for avoiding this and also providing real-time services when using HIPPI switches was investigated by Blanca researchers at Berkeley, who explored a time-division multiplexing (TDM) solution to the problem. Their local portion of Blanca consisted of three cascaded HIPPI switches with two or three hosts connected to each switch.
In the Berkeley scheme one host is designated as the master and is responsible for defining a TDM frame, frame synchronization, and scheduling requests received from the other hosts in each frame. Synchronization of the hosts and switches is accomplished by a combination of the master framing definition and HIPPI switch camp-on feature. Slots are assigned to hosts in each frame according to the quality-of-service bandwidth and latency requirements contained in their requests. An end-to-end HIPPI circuit is established, traffic sent, and the circuit terminated by the assigned host in each slot..
The Berkeley TDM scheme satisfied its goal of multiplexing real-time traffic through circuit-based HIPPI switches, demonstrating stable operation and traffic delivery within real-time latency bounds. However, its developers concluded that synchronization requirements limit the scheme to small networks, it does not allow bandwidth-sharing by non-real-time traffic, and it introduces a significant bandwidth overhead penalty.
In addition to local area switching within each site, the Casa testbed used their HIPPI switches, in conjunction with specially designed gateways, for wide area switching over the SONET links connecting the Casa sites. This was done by terminating local host HIPPI connections in a gateway device connecting the switch to an inter-site SONET link and relaying the packet through a HIPPI switch at other Casa sites on the path to the destination. Each intermediate site had a separate gateway and SONET link connecting it to each of its two neighboring sites (Figure 4-9).
Figure 4-9. Wide-Area HIPPI Switching
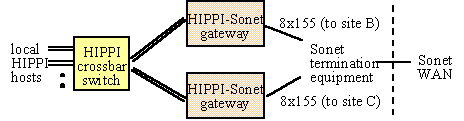
Buffering in the gateways and hosts allowed Casa to be operated as a store-and-forward packet switched network over its wide area end-to-end paths, in spite of the absence of buffering in the HIPPI switches. Routing was accomplished by defining a logical network-wide address for each host in the network and configuring a logical-physical address mapping table in each switch.
A host sending to a destination at another Casa site established a HIPPI connection between itself and the appropriate local gateway at its site, through one or more local HIPPI switches, for the duration of a single HIPPI packet transfer, with each packet constrained to the maximum IP packet size of 65 Kbytes. The local gateway is the endpoint of the HIPPI connection, exchanging HIPPI signaling with the local switch to control the flow of HIPPI bursts from the local host. A special gateway-gateway protocol is used across the wide area SONET link to send the HIPPI data and logical addressing information to the gateway at the next site and prevent buffer overflow in the receiving gateway.
Assume for this example that the destination host is at a third site. If the HIPPI switch port to the outgoing gateway at the intermediate site is not in use, a gateway-switch-gateway HIPPI connection is established at the intermediate site, and the first intermediate gateway proceeds to send its incoming data to the other gateway at that site. In this case the originating site and first intermediate gateways only buffer one complete HIPPI burst of the packet before proceeding to forward it, and do not need to buffer the entire packet. If the switch port to the outgoing gateway is in use, up to one full packet is buffered if necessary by the first intermediate gateway, which then signals the originating gateway to wait before sending another packet. Thus a form of cut-through is used, where the cut-through is applied whenever a full packet does not need to be buffered.
For the case where a higher layer retransmission protocol such as TCP is being used on the end-to-end path, a gateway will drop a packet if it cannot succeed in establishing a connection through a switch by a predefined timeout period. For situations where `raw' HIPPI packets are sent over the end-to-end path, such as was done for some Casa experiments in which TCP was not supported by one or more of the hosts, the timeout is disabled and the packet held until the connection can be made.
Gateway buffering thus allowed inter-site HIPPI switches to be decoupled in Casa, avoiding the tandem setup problem inherent in the direct connection of unbuffered HIPPI crossbar switches. HIPPI multiplexing latencies in this case were dictated by the choice of the 65 Kbyte maximum packet size allowed during a single local connection, in contrast with the real-time multiplexing achieved for local HIPPI switching by the Berkeley TDM scheme.
As part of their investigations into more efficient forms of data multiplexing for high speed networking, MIT explored a scheme based on the use of arbitrarily long data units defined for application layer efficiency, where the latter was referred to as Application Layer Framing (ALF). To achieve low latencies required for some types of traffic in this context, they studied the use of preemption in network switches. Simulation results for a variety of traffic loads showed that the required switch processing rate could be reduced by about a factor of 10 relative to cell switching.