


4.4.3 Transport
Work above the network layer was largely focused on the TCP and UDP transport protocols, along with a comparison of TCP with XTP. Key questions being asked prior to the testbed project were whether TCP in particular could run efficiently at gigabit rates on a host's native processor, or needed instead to be executed on an outboard implementation using varying degrees of specialized hardware.
The answer is obviously dependent on the power of the processor(s) used to execute the protocol, and indeed TCP/IP rates as high as 900 Mbps have been achieved on a dedicated Cray supercomputer in an I/O driver loopback mode. More generally, however, two factors were found to be of key importance for most computers: checksum computation and data movement.
Since this involves computation on every word of a packet, it is in general a significant overhead factor unless it can be combined with other per-word protocol operations. While this can be done if programmed I/O is used to move the data from the network interface to host memory, as discussed above the implementations done in the testbeds concluded that DMA was more efficient for the workstations used.
Thus, some of the host interfaces developed for the testbeds used special hardware to compute the checksum, passing the result to the host for received packets and inserting it into the header for outbound packets. The latter requires that the interface buffer a complete packet before transmission, with the checksum typically computed as the packet is moved from the host into the interface memory.
The fact that TCP carries its checksum in its header was a source of much debate among high speed designers, with some arguing for a standards change to allow the checksum to optionally be carried at the end of the TCP packet to reduce the interface buffering requirement. However, those arguing that the memory required was not a significant incremental cost compared to problems associated with a standards change won out, and the checksum continues to be carried in the header.
The second dominant overhead factor was found to be data movement between the interface and the application, that is to say, the operating system. All of the workstation operating systems in use at the start of the testbed effort typically performed multiple copy operations on packets, copying them between the network interface and operating system buffer space and between the latter and application memory space, with an additional packet read/store for checksum computation also often involved. Because workstation DRAM speed had not advanced significantly relative to processor advances during the span of the project, memory bandwidth was the major hardware impediment to gigabit I/O and packet copying was thus generally very costly compared to the time required to execute per-packet TCP protocol instructions.
Three of the testbed efforts addressed this problem in detail for workstations: the UPenn and Arizona/Bellcore ATM efforts in Aurora and the CMU workstation interfacing effort in Nectar. The result in all three cases was to reduce the data movement to a single transfer between the network interface and the application's memory space, achieved through techniques such as host memory page remapping or the use of I/O board memory as the intermediate `system memory'.
A fallout of this copy elimination is the resulting need for VCI and other demultiplexing while packets are in I/O board memory, in order to be able to map particular data streams into their associated application memory prior to DMA transfer [2].
Testbed investigations using supercomputers also found significant problems associated with protocol-related memory management. Experimentation with the Data Transfer Mechanism (DTM) software developed by NCSA for distributed applications communication revealed a number of memory-related factors affecting throughput. In particular, they found that the use of page alignment and restrictions on buffer sizes could provide as much as 65% performance improvement. The primary reason for the improvement was the resulting use of DMA transfers rather than copy operations, with multiple writes of smaller buffers preferable to a single large buffer write above a certain size [3]. Similar results were obtained in the development of Express in the Casa testbed, where mis-matches of packet sizes between different protocol layers within the host significantly degraded performance [4].
Two full outboard TCP/IP implementations were developed in the testbeds, one by LANL for use in Casa and one by UNC for use in Vistanet.
The LANL case was motivated by the need to support MPP supercomputers used in Casa which did not contain an internal high-performance TCP implementation, for example the TMC CM-2 and the Intel Paragon. A device called the Crossbar interface (CBI), originally designed to provide HIPPI networking support for hosts within Casa, was configured with an Intel 486 computer board and a Unix operating system to perform TCP/IP protocol processing. The CBI contained two HIPPI interfaces, one for connection to a host HIPPI interface and one for connection to a HIPPI switch or other HIPPI equipment (Figure 4-14).
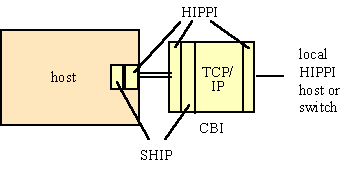
special hardware was used in the CBI for computing TCP checksums, and packet data buffering was handled in a flow-through manner without processor-based copying. The overall protocol processing model was thus similar to that of the workstation cases discussed above, except that a PC-class processor was used and the Unix operating system modified to allow processor interaction with the flow-through data hardware. A protocol called SHIP, for Simple Host Intersocket Protocol, was developed to present a standard TCP socket interface to applications on the host while providing relatively simple data transfers between the host and CBI. SHIP software was implemented as a library package on the Paragon and other computers.
A second instance of a full TCP outboard implementation was the NIU (Network Interface Unit) developed by UNC in Vistanet. The NIU was developed to provide external HIPPI and transport protocol support for the Pixel Planes 5 (PP5) multicomputer, a very fast graphics rendering computer developed by UNC and used for Vistanet experiments. The NIU moved data directly to and from PP5 processors using the PP5's data ring architecture, and provided a HIPPI interface for connection to a HIPPI switch (Figure 4-15).
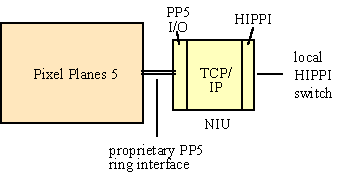
TCP/IP and UDP/IP protocol processing was supported using a 25 MHz SPARC processor, a custom multi-tasking kernel, and a custom protocol software implementation. Like the CBI, the NIU used hardware checksumming and flow-through data storage.
While numerous host-related bottlenecks were uncovered in the course of the testbed work, experiments nevertheless achieved record transfer rates. In particular, a TCP/IP transfer rate of 500 Mbps was measured between two Cray supercomputers over a 1000-mile HIPPI/SONET link in the Casa testbed, establishing a new high for wide area end-to-end transport. The TCP implementations used in these tests included the high bandwidth windowing and other extensions defined as part of the TCP standards.
For workstation-class machines, the Arizona/Bellcore effort achieved a UDP/IP rate of 516 Mbps using a DEC Alpha 3000/600 175 MHz processor with a Turbochannel I/O bus, the Bellcore Osiris ATM board and a collocated data source. This reflects the results of eliminating memory copying discussed above, and was obtained with the software-based checksum used in the implementation disabled. With UDP checksumming turned on, a throughput of approximately 440 Mbps was obtained.
Other results were constrained to lower rates by various factors, ranging from the hardware and software problems discussed above to the shared use of supercomputer data sources. The work by UPenn in Aurora resulted in a measured TCP/IP rate of 215 Mbps over ATM/SONET using two locally connected HP PA-RISC workstations and software checksumming. The LANL CBI outboard TCP/IP implementation in the Casa testbed gave a result of 300 Mbps over HIPPI when attached to a Cray, while the Vistanet UNC NIU outboard implementation achieved 350 Mbps for UDP/IP and approximately 200 Mbps for TCP/IP over HIPPI/ATM/SONET when used with a Cray as the data source.
The Nectar workstation effort by CMU included a careful evaluation of processor utilization, and so provides a good basis for extrapolating the testbed results in this area to newer machines. They performed TCP/IP measurements using a DEC Alpha 3000/400 133 MHz Turbochannel workstation, an external HIPPI CAB which provided hardware TCP checksumming, and the DEC OSF/1 v2.0 operating system modified to support single-copy data transfers. While the wCAB limited the maximum interface rate to 200 Mbps, host processor utilization measurements indicated that, if 100% of host processor cycles were used for communication processing, a maximum TCP/IP rate of close to 700 Mbps could be supported by the processor for a read/write memory transfer size of 128 Kbytes, and a rate of 500 Mbps for a transfer size of 64 Kbytes.
This suggests that, with a factor of 4 increase in overall processor speed relative to the Alpha processor used in the tests and the 64KB transfer size, a 622 Mbps ATM/SONET link could be filled while leaving approximately 75% of the processor available for application processing.
A comparative evaluation of TCP/IP and XTP was carried out by MCNC as part of the Vistanet testbed work, using all-software protocol implementations on a Cray YMP-EL (a low-end 100 MFLOP machine) connected to a HIPPI switch.
The TCP/IP code was optimized to use a combined checksum/copy operation and vectorized checksum computation, and included the high-speed extensions to the TCP standard.
The XTP code was an optimized implementation developed by the University of Virginia and ported to the Cray Unicos 8.0.2 operating system. Two different checksums were used with the XTP code, the one originally defined as part of the XTP standard and the checksum defined for TCP. The latter was used as a result of the original XTP checksum's high computational requirements on the Cray (the TCP checksum was adopted as part of the XTP standard in July 1994).
Measurements were carried out using 64KB packets for two conditions, one using the Cray's HIPPI driver in loopback mode and the second using a loopback at the external HIPPI switch. For error-free operation, TCP/IP provided higher throughput for both test modes, even when XTP used the TCP checksum.
A second set of measurements was made to determine the effect of packet errors on throughput. Since XTP included a selective retransmission mechanism while TCP did not, it was expected that XTP might show an improved relative performance for this case. For single packet errors XTP was slightly better than TCP/IP for bit error rates greater than about 2x10-9 , e.g. 118 vs 110 Mbps at a ber of 6x10-9. For a simulated burst error scenario in which three consecutive packets contained errors, XTP showed a more substantial gain over TCP/IP, giving a throughput of 115 vs 90 Mbps at a ber of 6x10-9.
Since a selective retransmission mechanism is currently undergoing standardization for TCP, the advantage shown by XTP under the above error conditions will most likely be eliminated. Thus there does not appear to be an incentive to change from the widely used TCP/IP standard to XTP for high speed operation, at least based on throughput and computational cost.
In addition to transport layer processing, data conversions required by hardware data representation conventions can constitute a major processing requirement at gigabit speeds. In the testbeds, conversions between Cray's 64-bit floating point representation and the IEEE 32-bit representation used by other testbed computers were found to be a significant bottleneck when standard vendor conversion software was used.
This problem was addressed by researchers in the Blanca and Casa testbeds as part of their application software support work. In both cases, Sun's XDR data representation conventions were used as a machine-independent format. Since the IEEE floating point format is used by XDR and by the non-Cray computers, they isolated the conversion processing to the Cray where its vector architecture could be exploited.
Measurements by NCSA using standard XDR conversion software on a Cray YMP resulted in a peak rate of only 11 Mbps, whereas a more efficient vector-based routine developed by NCSA for the project achieved a peak rate of 570 Mbps. SDSC and Parasoft found similar behavior in their Casa testbed work.